前言
该贴仅用于记录厉某的日常学习记录,由于博主本人记性较差,很容易忘记所学的内容,思来想去还是记录下来比较好。同时,博主的研究方向和导师的研究方向完全不一样,所以基本都靠自学,记录下自己的学习历程也是方便日后组内的学弟学妹(如果也和我一样······),毕竟自学总是要踩很多坑的。
2021-10-27
- 上午场
- 深度学习 - 炼丹入门
- MRI成像原理
- 下午场
- 损失函数:交叉熵
- nnU-Net for Brain Tumor Segmentation (BraTS 2020的分割赛道中获得第一名)
代码:nnU-Net for Brain Tumor Segmentation | Papers With Code
(Ps:意外发现了一个神奇的科研网站···)
总结:
- 针对脑肿瘤分割的nnUNet将原先网络架构中的softmax非线性替换为sigmoid。
- 将优化目标更改为三个肿瘤子区域(原先应该是在三个部分重叠的区域上进行的)。
- 还将交叉熵损失项替换为二元交叉熵,该二元交叉熵独立优化每个区域。
- 增加Batch size:随着BraTS数据集的规模不断扩大,nnUNet使用的小批量导致噪声梯度更大,这可能会减少过度拟合,但也会限制模型拟合训练数据的准确性。对于较大的数据集,增加批量大小(bias variance trade-off)可能是有益的。将批量大小从2增加到5,以提高模型精度。
- 更多的数据扩充:
- 增加图片旋转和缩放的概率(从0.2到0.3)
- 放缩比例从 (0.85, 1.25) to (0.65, 1.6)
- 分别为每个轴选择一个比例因子(单独放缩一个维度?)
- 使用概率为0.3的弹性变形(和前俩有啥区别)
- 使用概率为0.3的亮度增强。
- 增强Gamma变换的攻击性
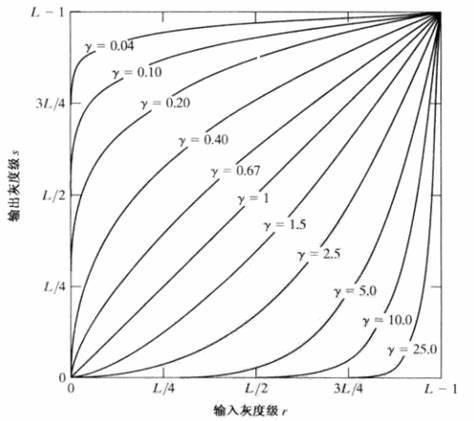
- 伽马变换:在图像处理中,将漂白(相机过曝)的图片或者过暗(曝光不足)的图片,进行修正。
- 如下所示,γ<1时作用是让过暗的图片颜色更明亮,γ>1时作用是让过亮的图片提升对比度。
- 攻击性的意思想必就是使得γ的取值更加极端。
- 夜晚场
- 数据增强
- 深度学习中的图像数据扩增(Data Augmentations)方法总结:常用传统扩增方法及应用
- 一股翻译味的总结:数据增强(Data Augmentation)
- 自动数据增强:AutoAugment: Learning Augmentation Policies from Data (arxiv.org)以及它的代码:tpu/autoaugment_utils.py at master · tensorflow/tpu (github.com)
- tensorflow可以使用keras进行自动的数据增强
- torch也可以使用transforms.Compose()来进行数据增强
2021-10-28
- 上午场
- 医学图像分割unet的改进方向:
- 半监督 弱监督 无监督分割
- domain adaptation系列,比如都是ct,不同设备拍的,如何迁移分割网络,甚至分割网络是自然图像(voc、coco)训练的。
- 生物图像(包含病理细胞等)如何标注。不同于传统医学图像,生物图像数据量极大,怎么标记effort更小是一个值得研究的问题。
- noisy label 问题。标注本身不好怎么办?
- 改loss,引进新的loss或针对存在的问题魔改loss。
- 改架构,引入各种奇奇怪怪的模块,channel attention、spatial attention、pixel attention等等。
- 改训练方法or学习方法,半监督 无监督 对比学习,都有很多方式可以尝试是否有更好的指标。
- 改应用方向。
- 计算机不能精确表示小数
神奇的网站:Floating Point Math (30000000000000004.com)
java中针对这一情况使用BigDecimal 可以表示一个任意大小且精度完全准确的浮点数
- 下午场 and 夜晚场
摸鱼···没怎么学习
2021-10-29
- 夜晚场
8.UNet_liver代码解析
- train_model()函数中有optimizer.zero_grad(),意思是把梯度置零,也就是把loss关于weight的导数变成0。以下代码块即梯度下降法,具体手写代码可以参考torch代码解析。
1 | # zero the parameter gradients |
transforms.Compose用于将多个图像处理步骤整合到一起。
用法:
- 训练:python main.py train
- 预测:python main.py test –ckpt=weights_19.pth
-
- 模型训练的代码中,没有写到forward,但是实际上
module(data)就等价于module.forward(data),只要在实例化一个对象中传入对应的参数就可以自动调用forward函数。
- 模型训练的代码中,没有写到forward,但是实际上
torch.cat函数
- 拼接两个张量,
torch.cat([a,b], dim = n)。三维张量时,dim=0指代通道数,dim=1指代行,dim=2指代列,函数中的dim即指定哪一个维度进行拼接。
- 拼接两个张量,
用脑肿瘤数据集时,由于脑肿瘤数据集只有一个通道,因此会提示:
RuntimeError:output with shape[1,512,512] doesnt match the broadcast shape[3,512,512]
除了Unet(3,1)需要改成Unet(1,1)之外,还需要改transforms.Normalize(mean=0.5,std=0.5)
nn.Linear()函数
全连接层的输入维度和上一层要对的上,不然会报错:
RuntimeError: CUDA error: CUBLAS_STATUS_INVALID_VALUE when calling cublasSgemm( handle, opa, opb, m, n, k, &alpha, a, lda, b, ldb, &beta, c, ldc)- 输入维度就是上一层输出大小(算上通道数的)
- 上一层输出后,需要用
.view(-1,)函数进行reshape,举例:- 上一层输出c14,大小为4 * 4 * 64,那在输入给全连接层之前,需要用
c14 = c14.view(-1, 64 * 4 * 4)才行,否则会报错。
- 上一层输出c14,大小为4 * 4 * 64,那在输入给全连接层之前,需要用
train_model时的维度问题
- 输出output和label可以看到,数据是以这样的形式保存的:
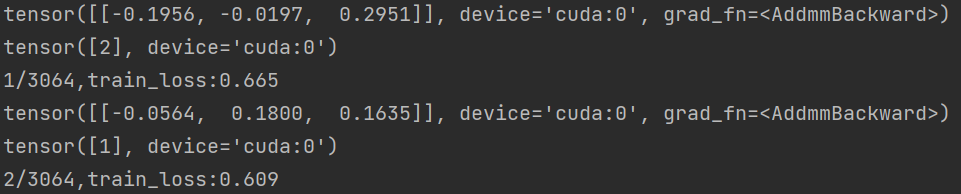
也就是在数据传入gpu后,即.to(device),张量的末尾会出现数据在哪个device上的信息,即使试图用label[0][0]来将张量用第一个数取出来,取出来的数也默认带有device的信息。
多任务学习中loss多次backward和loss加和后backward有区别吗? - 知乎 (zhihu.com):
有区别,最好还是先求各自任务的loss,之后再将loss求和,求和完后再进行梯度下降。
显存不足的问题:经测试发现,模拟器开手游挂机会占用300M的显存。
代码跑不通可能也是cuda的问题,可以设置一下用cpu跑:
1
2device = torch.device("cpu")
# device = torch.device("cuda" if torch.cuda.is_available() else "cpu")用cpu跑没问题的话就是cuda的问题。
分类网络的标签必须是从 0 开始,不然会出现最后一个标签越界的问题,当然在数据处理时也可以。
标签可以直接就是一个数,直接就是类别,比如第一类,那么label就是0。用
nn.CrossEntropyLoss()时会自动转换,因此不需要先转换成Onehot再求loss。如果先转换成Onehot,我目前的遇到的情况是会报错:RuntimeError: multi-target not supported at C:/cb/pytorch_1000000000000/work/aten/src\THCUNN/generic/ClassNLLCriterion.cu:15应该是本身传进去就是Onehot编码,然后loss函数又转化成了Onehot,导致一个样本对应了多个标签。
当然转换成Onehot还可以,只是目前我还没学到。
参数说明:
input has to be a 2D Tensor of size batch x n.This criterion expects a class index (0 to nClasses-1) as the target for each value of a 1D tensor of size n其标签必须为0~n-1,而且必须为1维的,如果设置标签为[nx1]的,则也会出现以上错误。
上一个点也说明,每次batch取出来后,batch_size个网络输出是合并在一起的,每个坐标和对应的标签一致。
记录一下出现的问题:把文件夹名字改为”0”、”1”、”2””后,会出现报错:
C:/cb/pytorch_1000000000000/work/aten/src/THCUNN/ClassNLLCriterion.cu:108: block: [0,0,0], thread: [0,0,0] Assertion t >= 0 && t < n_classes failed.RuntimeError: CUDA error: device-side assert triggered改回”1”、”2”、”3”不报错,但是需要在训练模型的时候,把传入的标签-1才能对应的上。
broadcast shape是什么?
Dataset可以简单想成一个列表,每个样本都有对应的索引 index,**__getitem__做的事情就是返回第index个样本的具体数据**:
9.各种损失函数
交叉熵损失:用于多分类有效,一般采用softmax激活函数 + 交叉熵损失函数。
logsoftmax():解决上溢和下溢的问题,加快运算速度,提高数据稳定性。在softmax()前又加了一个log()
Data augmentation
最全介绍:transforms的二十二个方法
2021-10-30
下午场:
11.leetcode每日一题
- ~x = - (x + 1)
- 如果想要消除一串数中成对的相同数字,可以采用异或的形式,二进制位中相同为0,不同为1.
12.模型训练
- 每个epoch之间是有关联的, 当前epoch取上一次的参数继续进行训练
13.batch是啥

2021-11-1
14.服务器文件相关
- 一次性传1000个以上的文件到服务器的功能还没有,因此可以压缩后上传。
- 服务器中使用rar和unrar需要自己安装,但是安装会比较麻烦,因此建议使用zip。
- 不能偷懒直接把rar的文件名字改成zip,虽然也能打开,可以正常解压和使用,但是在linux系统下使用时会提示这不是一个zip文件,建议右键文件时选择”添加到压缩文件“后选择zip格式。
- 解压指令为:unzip -x *.zip
15.脊索瘤类似的肿瘤——垂体瘤数据集的一些问题
图片大小的问题:总共3064张二维图片,以及对应3064张mask图片,大部分都是512 * 512大小,但是有几张是256 * 256大小,导致train()的时候报错。如果batch采样到了256 * 256大小的图片就会因为数据大小不一致报错。因此需要遍历每张图片,判断img.size()是否等于512。
图片格式的问题:图片是mat格式,每个mat格式对应一个struct,里面有”tumoprMask”、”tumorBorder”等等。
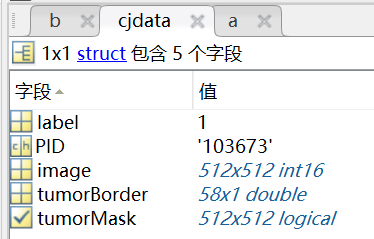
读mat的时候就可以通过【.cjdata.image】获取图像,再通过【.cjdata.tumorMask】获取mask,tumorBorder暂时不知道有啥用。对于格式的转换,这里用了比较麻烦的方法,就是先将mat转换为nii(用make_nii()),再将nii转换为png。
图片是二维单通道图片,然而unet_liver用的是RGB通道的图片,因此转换的时候需要用
img = img.convert("RGB")来进行颜色空间的相互转换。
2021-11-2
16.论文解读:Very Deep Convolutional Networks for Large-Scale Image Recognition(VGG)
- 神经网络可视化工具
- VGG原理:采用连续的几个3×3卷积核代替AlexNet中的较大卷积核(11x11,7x7,5x5),优点为:
- 增加层数,提升网络深度,多层非线性层可以增加网络深度来保证学习更复杂的模式
- 3*3卷积的参数更小
- 3*3卷积核更有利于保持图像性质
- 论文验证了通过不断加深网络结构可以提升性能。
17.分类和分割的区别?
- 或许可以先分割后再分类,看一下速度和准确度。
2021-11-3
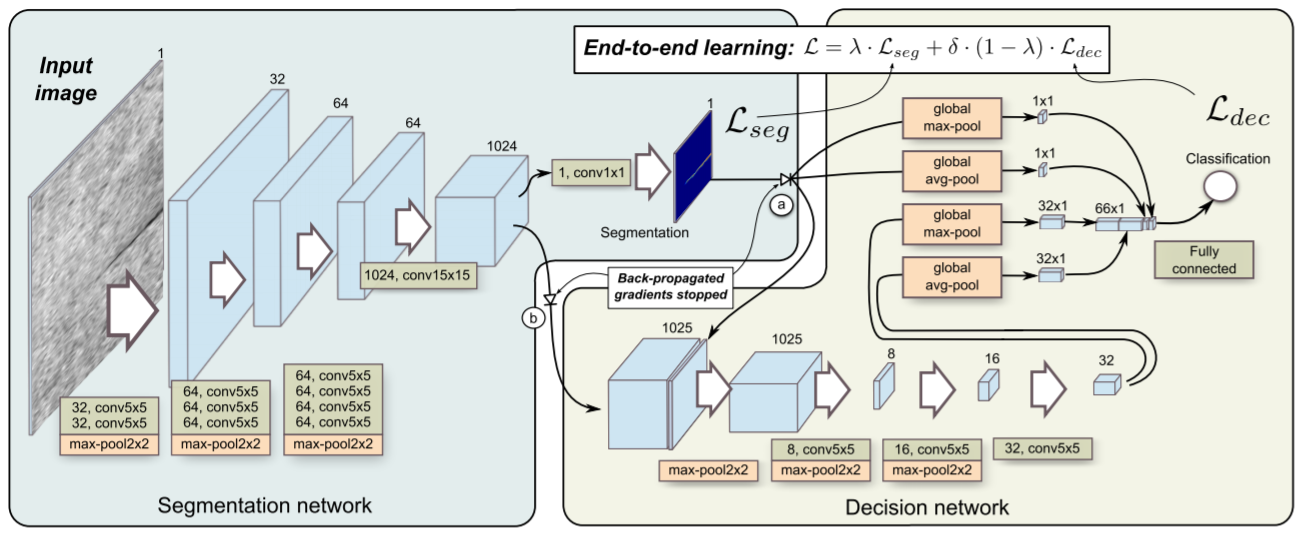
18.论文解读:End-to-end training of a two-stage neural network for defect detection
-
- 主要优势为:只需要25-30个有缺陷的样本就可完成分类,所用样本极少。
- 感觉如此少的样本可能是过拟合了,对作者自己的数据集可达到很好的效果,但是用其他的可能不太行。
- 在分割网络最后面(1*1卷积处)使用sigmoid激活函数,生成二值掩码。
- 作者对标注类型的影响、损失函数的选择(分割网络)、输入分辨率的大小、是否对输入图像进行旋转 这四个方面对模型精度的影响进行探讨。
- 结果为:分割网络使用交叉熵损失函数,模型的精度要明显优于MSE损失函数。
- 其他无明显变化(用在医学图像中,CT / MRI切片的方向是否应该一致?有些是横着切,有些是竖着)
- 主要优势为:只需要25-30个有缺陷的样本就可完成分类,所用样本极少。
-
为了保证小细节被保留下来,使用的是max-pool2x2,而不是使用stride=2的卷积
在下采样到最底层后输出粗略的分割图,然后继续进行分类。作者认为相比于像素集的损失,判断是否有缺陷的分类结果更为重要。
优化点:
Dynamically balanced loss:融合了分割loss和分类loss,融合为一种简单统一loss,允许进行共同学习。新的loss为:
$$
L_{total} = \lambda · L_{seg} + \sigma · (1 - \lambda) · L_{cls}
$$$\sigma $的作用:额外的分类损失权重,防止分类的loss占据总的loss
$\lambda$的作用:平衡不同网络在最终loss中的贡献。
$$
\lambda = 1 - n / total_epoch
$$
n为当前epoch的索引值。这样在刚开始训练网络的时候,$\lambda$接近于1,分类的loss几乎为0,就能做到先训练分割网络,再训练分类网络。梯度回传?/梯度流?的调整
在分割网络输出segmentation后禁止分类网络的梯度回传,给回传到分割网络的梯度设置一个0的权重。
交替抽样
Loss weighting for positive pixels:当分割出来的部分存在不确定性,无法判断是否存在缺陷时,通过加权分割的损失来实现标签不同位置的重要性。
17.深度学习中的trick:
trick : it works but maybe nobody knows why (就是可行,也不知道为什么。)
hack : it works and only a few know why (直达痛点,缺乏设计,但是原因说得清)
2021-11-4
- 下午场
18.残差神经网络(ResNet) 参考:残差神经网络(ResNet)- 知乎、ResNet详解与分析 - 博客园、残差网络(ResNet)- 博客园[3]
- 主要贡献:发现了”退化现象“(Degradation),针对退化现象发明了”快捷连接“(Shortcut connection)”,消除了深度过大的神经网络训练困难的问题。
- 神经网络的每一层可以看成是使用一个函数对变量的一次计算。
- 为什么层数深了后容易出现退化?
- 浅层网络层数越高性能越好:通过AlexNet让大家发现,网络越深准确率越高(复杂度更高,具有更大的假设空间,表达能力更强,可以对潜在的映射关系拟合更好)。但是ResNet的团队在网络后面增加恒等变换层后发现,随着网络层数不断加深,准确率先提高后出现大幅度的降低,也就是退化。
- 训练集上的性能下降,可以排除过拟合,BN层的引入也基本解决了plain net的梯度消失和梯度爆炸问题。
- 过拟合:过拟合(定义、出现的原因4种、解决方案7种)
- 欠拟合:由于统计模型使用的参数过少,以至于得到的模型难以拟合观测数据(训练数据)的现象。欠拟合一般不怎么严重,欠拟合了就多训练几次即可。主要还是过拟合。
- BN层总结:
- 主要作用是加速网络收敛,一定程度上减少过拟合的发生。
- 主要流程为:计算样本均值、计算样本方差、样本数据标准化处理、进行平移和缩放处理(这一步可能使得BN层在一定程度上减少过拟合的情况)。
- 主要思路为:让每个隐层节点的激活输入分布固定下来,用normalization将输入限制到一个固定的输入。
- 一般加在Relu层之后,Dropout层之前。Dropout层通常加在网络末尾,网络输出前一层。
- 主要原因:与传统的机器学习相比,深度学习的关键特征在于网络层数更深、非线性转换(激活)、自动的特征提取和特征转换,其中,非线性转换是关键目标,它将数据映射到高纬空间以便于更好的完成“数据分类”。随着网络深度的不断增大,所引入的激活函数也越来越多,数据被映射到更加离散的空间,此时已经难以让数据回到原点(恒等变换)。或者说,神经网络将这些数据映射回原点所需要的计算量,已经远远超过我们所能承受的。
- 梯度破碎?:参考[3]中提到,残差网络实际上解决的是梯度破碎的问题。在浅层神经网络中,梯度呈现为棕色噪声(brown noise)。在标准的前馈神经网络中,随着深度的增加,梯度逐渐呈现为白噪声,神经元梯度的相关性按指数级减少。同时,梯度的空间结构也随着深度增加被逐渐消除。这也就是梯度破碎现象。
- 梯度破碎为什么是一个问题呢?这是因为许多优化方法假设梯度在相邻点上是相似的,破碎的梯度会大大减小这类优化方法的有效性。另外,如果梯度表现得像白噪声,那么某个神经元对网络输出的影响将会很不稳定。
- 针对以上现象,ResNet中增加了线性转换分支,在线性转换和非线性转换之间寻求一个平衡。
- 拙著···还挺谦虚的
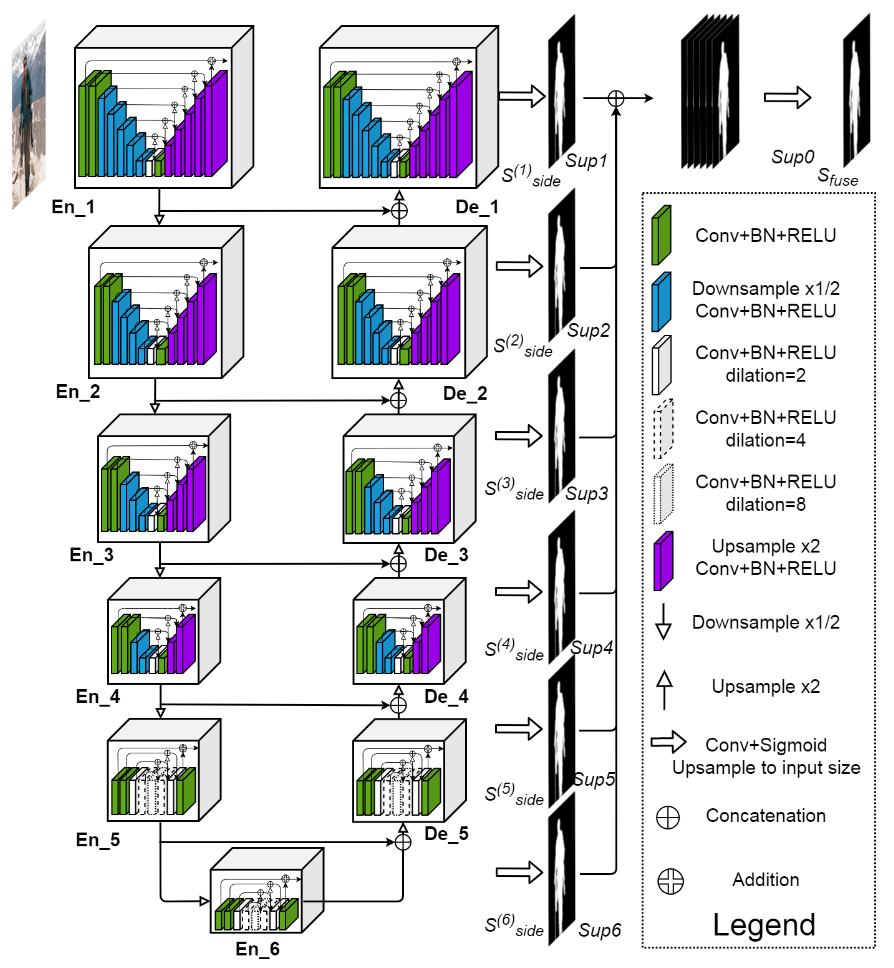
19.U^2 Net: Going Deeper with Nested U-Structure for Salient Object Detection
流程图:
19.如何写人工智能SCI?(20 封私信) 如何写人工智能方面的sci? - 知乎 (zhihu.com)
2021-11-6
- 下午场
20.python读取文件顺序问题:
python在读取文件夹下面的文件的时候,是按键值来排序的,因此会出现读入顺序为”1.png,10.png,2.png……“这样的情况,如果对读取的文件顺序有要求,需要将代码改成:
1 | mylist = os.listdir(png_path) |
21.如何画神经网络模型训练时的loss曲线、准确率曲线、dice曲线等
(PS: 损失函数请看第9点)
为什么需要激活函数:数据的分布绝大多数是非线性的,而一般神经网络的计算是线性的,引入激活函数也就能在网络中引入非线性,强化网络的学习能力。
各激活函数优缺点总结:
Sigmoid($∫$):
公式:
$$
sigmoid(x) = 1 / 1 + e^{-x}
$$优点:
- 平滑、易于求导
缺点:
- 计算量大(正向和反向传播都包含幂运算和除法)
- 反向传播求误差梯度时,求导涉及除法
- 取值范围是[0,0.25],网络层数深了以后容易出现梯度消失的情况。
- Sigmoid的输出不是0均值(函数值>0),这会使得当前层的神经网络用上一层的非0均值作为输入,随着网络的加深会逐渐改变数据的分布。
tanh(双曲正切,$∫$):
公式:
$$
tanh(x) = e^x - e^{-x} / e^x + e^{-x}
$$相当于是将sigmoid平移后拉伸,相比于sigmoid:
- tanh输出范围为(-1,1),是0均值
- 导数范围在(0,1),梯度消失的问题得到缓解,但仍然存在
ReLU( _/ )
公式:
$$
ReLU(x) = max(0, x)
$$特性:
- 取值为[0, x],范围比前两种大,减少了梯度消失的情况,随之而来的是梯度爆炸的问题。
- 深度学习的目标就是从大量样本数据的密集矩阵转换为稀疏矩阵,保留数据的关键信息,去除噪音,这样的模型具有鲁棒性。将所有小于0的特征简单地消除,就是去噪音的过程,但是也会导致模型无法学习到所有特征。如果学习率太大,就会导致网络的大部分神经元处于“dead”状态,所以使用ReLU的网络,学习率不能设置太大。
ReLU变体:给 x < 0 的部分设置一个很小的梯度$\alpha$
- Leaky ReLU: $\alpha$为常数,一般设置为0.01。效果比ReLU好,但是效果不稳定,实际中Leaky ReLU用的不多。
- PReLU(Parametric ReLU):$\alpha$作为一个可学习的参数,会在训练过程中更新。
- RReLU(Random ReLU): 负值的斜率在训练中是随机的,在之后的测试中就变成固定的。训练环节中,x<0部分的斜率是一个从均匀分布中随机抽取的数值。
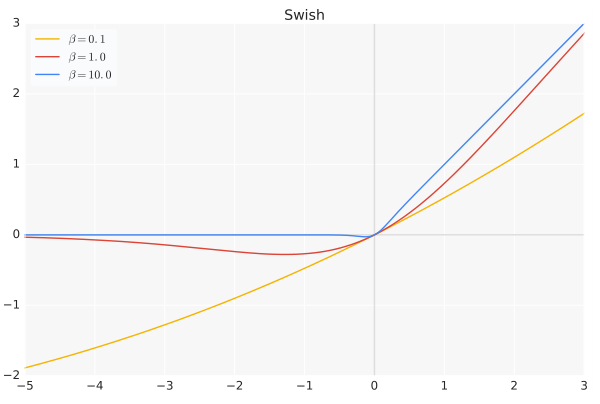
Swish:
公式:
$$
swish(x) = x · sigmoid(\beta x)
$$其中$\beta$是一个常数或者可训练的参数。
Mish
公式:
$$
Mish(x) = x·tanh(ln(1 + e^x))
$$
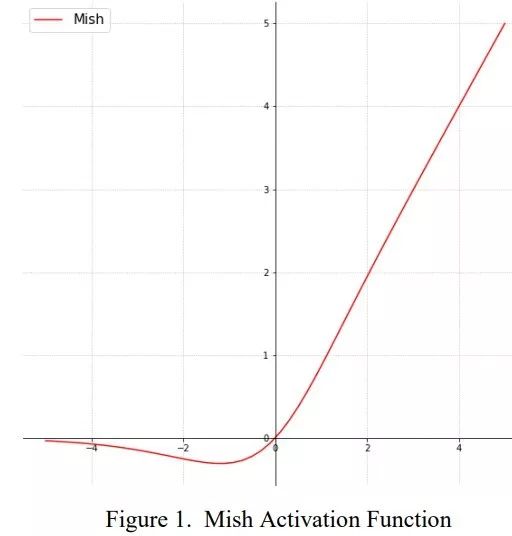
- 特点:是比较新的SOTA激活函数。个人感觉和Swish差不多。
激活函数尝试经验
- 首先使用ReLU,速度最快,然后观察模型的表现。
- 如果ReLU效果不是很好,可以尝试Leaky ReLU或Maxout等变种。
- 尝试tanh正切函数(以零点为中心,零点处梯度为1)。
- 在深度不是特别深的CNN中,激活函数的影响一般不会太大。
- Kaggle比赛,试试Mish?
2021-11-8
- 下午场
23.同一个模型用tf,pytorch,theano实现,差距可能会较大。 参考
24.loss计算部分代码为什么要加.item()?
加了.item()之后返回的是一个精度更高的浮点型数据,所以我们在求loss或者accuracy的时候一般使用item(),而不是取出张量对应的元素。
2021-11-9
- 夜晚场
25.UNet + CNN
multi-task network,
27.重要资料:
- 2020年最新SCI期刊影响因子以及JCR分区表
- 医学图像分割优质开源代码 - 知乎 (zhihu.com)
- 医学图像处理领域值得关注的期刊和会议 - 知乎 (zhihu.com)
- 医学图像处理领域值得关注的期刊和会议 - better - 知乎 (zhihu.com)
- 图像领域有哪些高级期刊与顶会? - 知乎 (zhihu.com)
- 医学图像处理领域期刊和会议
- 再加一个SCI三区: Medical physics
- 不知道能不能用的数据集:ret-1 — CRCNS.org
28.一些想法:3D res-UNet ? Multitask Unet?
brain tumor dataset (figshare.com)
cjdata.label:1 表示脑膜瘤,2 表示神经胶质瘤,3 表示垂体瘤,可以拿来做一下分割 + 分类
多模态(4张图片,根据mask切割图片,即只找出有病灶的区域,4张拼接在一起看看效果)
用PW减少网络参数
2021-11-10
- 多个不同尺寸的卷积核,提高对不同尺度特征的适应能力
- PW卷积(Pointwise Convolution),1*1卷积,主要用于减少参数量,可以用于数据升维和降维
- 参数量计算方式:filter size * 前一层特征图的通道数 * 当前层的filter数量
- 多个小尺寸卷积核替代大卷积核,加深网络的同时减少参数量
- Bottleneck结构大大减少网络参数量
- 思想:先用PW对数据进行降维,再进行常规卷积,最后PW对数据进行升维
- 深度可分离卷积
- 逐通道卷积:就是每个通道对应一个filter,但是没有有效地利用不同通道再相同空间位置上的feature信息,因此需要PW卷积将这些feature map进行组合生成新的feature map。
- 逐点卷积:PW卷积,将上一步的map在深度方向上进行加权组合。
- 总的参数量 = 逐通道卷积 + 逐点卷积
30.概念:MICCAI+BraTS+多模态t1,t2,flair,t1c+HGG,LGG+WT,ET,TC
2021-11-15
31.试着去找一下数据集:Ependymomas、Diffuse Intrinsic Pontine Glioma、Medulloblastoma、Pilocytic
32.Python自带的random库,numpy的随机库,torch的随机函数
33.Multitask Classification and Segmentation for Cancer Diagnosis in Mammography
2021-11-16
34.模型记录:
最早的一份网络(UNet + CNN,两端输出),训练时间为21:02:48 ~ 23:50:27。batch_size=12,epoch=30。
- 问题:模型训练完保存参数的时候又没注意命名的问题导致报错,loss没存下来。
- 以后代码中有一个变量多次出现但是要修改命名后,在Pycharm中可以用Shift + F6或者右键变量 -> Refactor -> Rename批量修改。
- 经实验后发现,classification的loss很大,比segmentation要大得多,因此在联合loss处,需要在classification的loss前面加一个系数,防止分类的loss占据总loss的大部分,详见第18点。
- 可以设定一个动态调整的系数,当某一任务的loss过大时,就给他较大的权重。
一开始以为是RGB图像与灰度图像的问题,导致加了分类网络后分割效果也变差了,但是发现分割网络并不需要RGB的颜色信息,一般也都是转换为灰度图像来做的,那就说明是其他问题。看了下数据集发现每一个肿瘤中有很多肿瘤都非常的小,感觉还是mask太小的问题,导致分类和分割都不太准。
(11-17)模型在验证集上效果不好,有点过拟合了,之后要做的:
- 更积极的数据增广
- 交叉验证
- 去掉全连接层(SPP layer)
- 数据预处理:
- 加入ResNet以及1*1卷积
- 动态loss
- 动态learning rate
- tensorborad绘制loss曲线
- 如何利用CT的HU值判断肿瘤区域(结果发现数据集是MRI)
- 加入先验知识
- Decoder部分加一个SE Block
- 正负样本不均匀的问题: 裁剪图像
- 用PIL库中的getbbox函数直接获得图像的最小包围盒,然后用.crop()函数进行裁剪
- 用户交互
- MRI图重建:一文掌握图像超分辨率重建(算法原理、Pytorch实现)——含完整代码和数据
(12-11)模型在增加了epoch、data augmentation、res后效果变得奇差,等待重新训练。
- (12-16)问题解决,是data augmentation图像和标签不对应的问题。
论文题目:Multitask learning for brain tumor segmentation and classification
2021-11-17
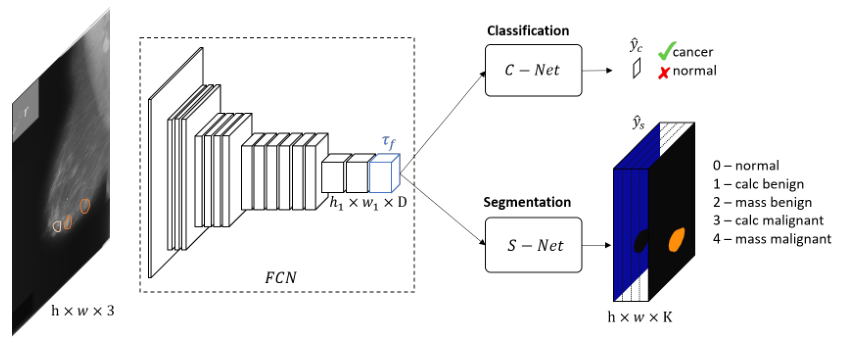
36.论文解读:Multitask Classification and Segmentation for Cancer Diagnosis in Mammography(MIDL 2019)
- 该方案结合了像素级分割和全局图像级分类注释
- 联合训练能够学习对这两项任务都有益的共享表征
- 类别不平衡问题(“健康”区域与其他病变类别相比占优势)
- C-Net和S-Net的交接处定义为共享张量
- C-Net使用binary cross entropy,S-Net使用cross-entropy
- C-Net的结果用AUC评估,S-Net用Mean Dice评估
- 在deconvolution layer 和convolution layer 后面加batchnorm和scale层(BN)后再concat
37.Pytorch详解BCELoss和BCEWithLogitsLoss计算方式
38.PyTorch 图像分类器 - PyTorch官方教程中文版 (panchuang.net)
39.pytorch训练过程中Loss的保存与读取、绘制Loss图
2021-11-18
40.attention机制:主要思路就是带权求和。参考:深度学习attention机制中的Q,K,V分别是从哪来的?
- Q、K、V是什么?copy 一个回答:假如一个男生B,面对许多个潜在交往对象B1,B2,B3…,他想知道自己谁跟自己最匹配,应该把最多的注意力放在哪一个上。那么他需要这么做:
- 他要把自己的实际条件用某种方法表示出来,这就是Value;
- 他要定一个自己期望对象的标准,就是Query;
- 别人也有期望对象标准的,他要给出一个供别人参考的数据,当然不能直接用自己真实的条件,总要包装一下,这就是Key;
- 他用自己的标准去跟每一个人的Key比对一下(Q*K),当然也可以跟自己比对,然后用softmax求出权重,就知道自己的注意力应该放在谁身上了,有可能是自己哦!
- add和concate的区别:
ResNet使用add来拼接输出和未经网络处理的部分,Unet用concate来实现跳层连接
concate是通道数相加,直接对通道数进行拼接
add是特征图相加,通道数不变,相加时两个feature map的大小以及通道数应该得是一样的。
42.先验知识:给模型加入先验知识
43.Pytorch的nn.BCEWithLogitsLoss()和nn.BCELoss()
- 本质上没有区别,在BCELoss上增加了一个logits函数,也就是sigmoid函数。
- 如果网络本身在输出结果的时候已经用sigmoid去处理了,算loss的时候用nn.BCEWithLogitsLoss()…那么就会相当于预测结果算了两次sigmoid,可能会出现各种奇奇怪怪的问题——比如网络收敛不了(流泪猫猫头.jpg)
2021-11-20
44.医学图像的突出特征:
总体上来说,医学图像相比于自然图像(通过可见光成像)有以下四点区别:
医学图像的模态(格式)更加多样化,如X-ray、CT、MRI以及超声等等,当然也包括一些常见的RGB图像(如眼底视网膜图像)。不同模态图像反应的信息侧重点是不一样的。比如X-ray观察骨骼更清晰,CT可以反应组织和器官出血,MRI适合观察软组织。而且不同型号的成像设备得到的成像结果有一定差异。
医学图像的像素值范围与自然图像(0~255)有很大差别,如CT一般会上千。
噪声。由于成像设备、成像原理以及个体自身差异的影响,医学图像一般会含有很多噪声。由于噪声对于位置和空间约束是独立的,从而可以利用噪声的分布来实现降噪,但是在抑制噪声的同时也需要考虑图像细节的保留问题。
伪影。伪影一般是在图像配准或三维重建时产生(如CT),从原理上来,只能减少,无法消除。
45.三维多模态nii处理
- 将四个模态图像(155,240,240)及相应的mask合并,同时人工加入5个黑色切片,前面3个后面2个,最后每个模态图像都变为(160,240,240)。这样做是为了后面的分块。
- 标准化:BraTS采用了T1,T2,flair,T1ce这四个序列的MR图像,这四个序列是不同模态的图像,因此图像对比度也不一样,所以采用z-score方式来对每个模态图像分别进行标准化,也就是z-score也就是$$(x-\mu)/\sigma$$。
- 对医学图像分割未来发展方向的一些讨论
46.空洞卷积(dilated convolution)
字面意思就是在标准的卷积里注入空洞,以此来增加感受野,相比正常的convolution多了一个超参数,用来指定kernel的间隔数量(正常的convolution是1)
传统CNN的一些问题:
- 内部数据结构丢失,空间层级信息丢失
- 小物体信息无法重建
想法:设计一种新的卷积操作,不通过池化也能有较大的感受野看到更多的信息。
dilated的好处是不做pooling损失信息的情况下,加大了感受野,让每个卷积输出都包含较大范围的信息。
针对空洞卷积的问题:通向标准化设计:Hybrid Dilated Convolution (HDC)
47.patch是什么?
定义:patch可以理解为是图像块,当需要处理的图像分辨率太大而显存、算力等资源受限时,就可以将图像划分成一个个小块,这些小块就是patch
为什么不用resize?:进行图像分割时,由于是dense prediction,像素级的预测需要尽可能的精确。而resize是对图像进行插值,本质上是一种滤波,会造成像素级上的信息损失。某些位置上的像素值本身就是由多个位置加权计算出来的,从而限制了模型精度的上限。
2021-11-23
49.先验知识:用先验知识控制训练过程,使得算法在不违背先验知识,或者可也称为人工强规则的前提下,获取最好的结果。
50.pytorch语义分割中CrossEntropy、FocalLoss和DiceLoss三类损失函数的理解与分析
52.保存训练时产生的loss等数据:
2021-11-24
54.图像分割涨点技巧!从39个Kaggle竞赛中总结出的分割Tips和Tricks
55.轻量级实时语义分割经典BiSeNet及其进化BiSeNet v2
56.交叉验证:
2021-12-06
今日要看论文:Two-Stage Cascaded U-Net: 1st Place Solution to BraTS Challenge 2019 Segmentation Task
57.多任务学习中loss权重确定方法:
- 每次只训练一个任务,冻结其他所有任务,最后一起训练所有任务。
- 每次训练单个任务到收敛后,记录它的梯度。之后一起训练时,分别用各自收敛时梯度的倒数对每个任务做平衡,然后进行归一化。
- 多任务学习中的自动权重调整方法 - 知乎 (zhihu.com)
- 多任务学习优化(Optimization in Multi-task learning) - 知乎 (zhihu.com)
2021-12-07
58.金字塔池化
在使用金字塔池化(SPP)时,直接用函数一直报错【missing 1 required positional argument】,提示最后一个参数output_num一直没有传进去,感觉python还是没学好,不知道怎么传,于是选择了另一个函数文件,是放在类里面完成的。
需要注意的是调用类时,需要先实例化:
spp_layer = SPPLayer(4,'max_pool'),然后再将上一层传给spp_layer,这样返回spp层。参数计算方式:在函数文件中,层数是作为list传的,比如output_num = [4, 2, 1]。这样就有$4^2$ + $2^2$ + $1^2 = 21$个分块,然后分块数 * 上一层通道数等于spp_layer变形成一维时的长度。而类文件中层数num_levels是一个数字,传进去后从1开始一直遍历到num_levels,并求平方和。这是需要注意的。
输出spp的shape后可以看到是一个二维的,第一个维度是分块数,第二个维度是分块数 * 通道数,不过输入给全连接层的时候不用再view成一维的,直接输入进去就可以了。
金字塔池化的画法:
2021-12-08
59.数据增强的一些疑问:
data augmentation如果不保存的话,输入到模型的图片数量上没有变多,但是种类上大大增加了,因为每次采集数据都做一次transform。这样的话每个 epoch 输入进来的图片几乎不会是一模一样的,这达到了样本多样性的功能。每个epoch里预处理都是随机的,实际上再增加迭代次数,就已经扩充了本身数据集。
transform并不支持对图像和对应的label同时进行操作,同时由于旋转等都是随机进行操作,因此可以写出一个transforms.Compose之后,设定一个随机数
np.random.randint(2147483647),然后在进行图像和label的数据增强前分别进行两次应用随机数。albumentations 数据增强工具的使用:使用该工具可以同时对两幅图像进行操作。
- 使用方法可以参考:
- Albumentation使用指南
- Using Albumentations for a semantic segmentation task - Albumentations Documentation
- 安装:pip install albumentations -i https://pypi.tuna.tsinghua.edu.cn/simple
- 也可以用conda安装,但是由于服务器里的pytorch是用pip安装的,输入pip list可以看到很多包,输入conda list就一个包也看不到,用
conda intall albumentation之后就会神奇的发现pytorch不见了!暂时不知道为啥,只能用pip安装,直接安装时会报错提示速度太慢,要加清华源。 Building wheel for opencv-python (PEP 517) ... -安装时可能会在这一步一直卡着,看了Stackoverflow的回答后,先输入pip install --upgrade pip setuptools wheel,然后就能非常顺畅地安装了。
- 有一个问题是,即使设置了随机数的种子,每次运行的结果还是一样的,就很奇怪,暂时先不用了。
- 2021-12-15更新:现在解决了,不能使用
seed = torch.manual_seed(2147483647)
- 2021-12-15更新:现在解决了,不能使用
- 使用方法可以参考:
2021-12-09
60.在参加了39场Kaggle比赛之后,有人总结了一份图像分割炼丹的「奇技淫巧」 - 知乎 (zhihu.com)
63.pytorch框架分类器各个子类准确率计算代码_未名方略-CSDN博客
Pytorch 计算分类器准确率(总分类及子分类)_Smile-CSDN博客_pytorch 准确率
64.找最大连通图:Matlab得到二值图像中最大连通区域
65.使用pycharm查看矩阵变量:SciView的正确使用
66.crossentropyloss()内部自带Softmax层,因此分类网络的输出不需要再通过sigmoid(二分类)或者softmax(多分类)。还有Unet最后输出不需要sigmoid,之前loss出现负数的时候加上了sigmoid,后来发现第一个epoch就收敛不了了。
2021-12-19
67.漫水填充算法参考文献:
- OpenCV技巧 | 二值图孔洞填充方法与实现(附源码)
- Filling holes in an image using OpenCV ( Python / C++ ) | LearnOpenCV #
68.pytorch冻结某些层进行训练:
2021-12-23
69.focal loss的核心参数有两个,一个是$\alpha$, 一个是$\gamma$。其中$\alpha$是类别相关的,而$\gamma$是类别无关的。
- $\gamma$根据真实标签对应的输出概率来决定此次预测loss的权重,概率大说明这是简单任务,权重减小,概率小说明这是困难任务,权重加大,控制难易样本。(这是Focal loss的核心功能)
- $\alpha$是给数量少的类别增大权重,给数量多的类别减少权重,控制类别不平衡。
- 何恺明大神的「Focal Loss」,如何更好地理解? - 知乎 (zhihu.com) - by 苏剑林
70.要投的期刊:MEDICAL PHYSICS
2022-01-02
71.新手炼丹经验总结 - 知乎 (zhihu.com):“我个人的经验是,优化器用 AdamW(少数地方用 SGD with Momentum),学习率推荐 cosine learning rate,初始值选 3e-4(SGD 可以选 0.1),激活函数选 PReLU。Batchsize 取 64,尽量用多卡,如果用 torch 的话记得用 DistributedDataParallel。”
2021年下半学期的学习记录就到这里了,之后就忙于开题和写论文,还有一系列生活琐事,明年继续吧!

